PHP爬虫框架 第2章 PHP Simple HTML DOM Parser
PHP爬虫框架 第2章 PHP Simple HTML DOM Parser
一、介绍
这是一款 html 解析框架,它提供了类似于 jquery 的 api,使得我们操作元素,获取元素非常的方便。
它的缺点就是因为需要加载和分析大量 dom 树结构,因此占用内存空间较大,同时它的解析速度也不是很快,不过它的使用便捷性是其它框架无法比拟的。
如果你要抓取一个少量的数据,那么它很适合你。
PHP Simple HTML DOM Parser:支持 CSS 选择器,可以解析 HTML 文件
二、安装
通过 composer 安装
composer require sunra/php-simple-html-dom-parser
三、使用
3.1、快速开始
①、获得 HTML 元素
//使用url和file都可以创建DOM
$html = file_get_html('http://www.google.com/');
//找到所有图片
foreach($html->find('img') as $element)
echo $element->src;
//找到所有链接
foreach($html->find('a') as $element)
echo $element->href;
②、修改HTML元素
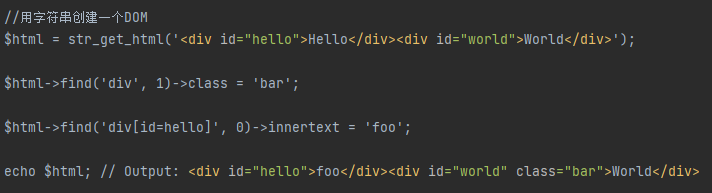
③、获得 HTML 内容
//把 google.com 以纯文本的形式输出
echo file_get_html('http://www.google.com/')->plaintext;
④、演示
// Create DOM from URL
$html = file_get_html('http://slashdot.org/');
//查找所有的文字块,我在测试的这段代码的时候发生错误.估计是目标网站有做修改
foreach($html->find('div.article') as $article) {
$item['title'] = $article->find('div.title', 0)->plaintext;
$item['intro'] = $article->find('div.intro', 0)->plaintext;
$item['details'] = $article->find('div.details', 0)->plaintext;
$articles[] = $item;
}
print_r($articles);
3.2、如何创建HTML DOM对象?
①、捷径
//字符串创建DOM对象
$html = str_get_html('Hello!');
//URL创建
$html = file_get_html('http://www.google.com/');
//文件创建
$html = file_get_html('test.htm');
②、面向对象
// 创建DOM对象
$html = new simple_html_dom();
// 字符串载入
$html->load('Hello!');
// URL载入
$html->load_file('http://www.google.com/');
// 文件载入
$html->load_file('test.htm');
3.3、如何查找HTML?
①、基础
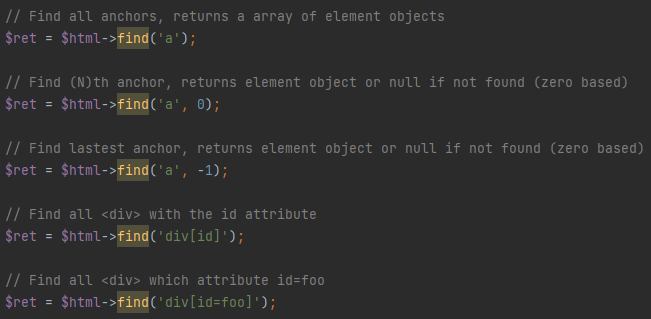
②、高级
// 查找所有id=foo的元素
$ret = $html->find('#foo');
// 查找所有class=foo的元素
$ret = $html->find('.foo');
// 查找所有拥有 id属性的元素
$ret = $html->find('*[id]');
// 查找所有 anchors 和 images标记
$ret = $html->find('a, img');
// 查找所有有"title"属性的anchors and images
$ret = $html->find('a[title], img[title]');
③、层级选择器
过滤 描述
[attribute] 匹配具有指定属性的元素.
[!attribute] 匹配不具有指定属性的元素。
[attribute=value] 匹配具有指定属性值的元素
[attribute!=value] 匹配不具有指定属性值的元素
[attribute^=value] 匹配具有指定属性值开始的元素
[attribute$=value] 匹配具有指定属性值结束的元素
[attribute*=value] 匹配具有指定属性的元素,且该属性包含了一定的值
④、嵌套选择器
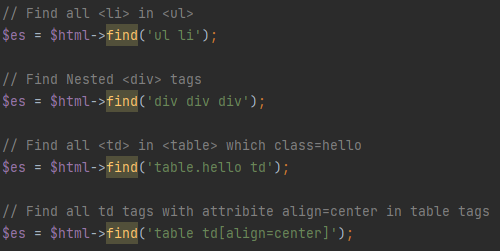
⑤、属性过滤
// 查找所有文字块
$es = $html->find('text');
// Find all comment () blocks
$es = $html->find('comment');
⑥、文本和内容
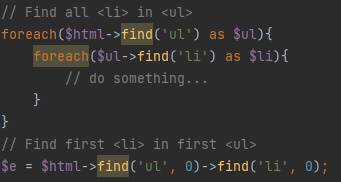
3.4、如何访问 html 元素的属性?
①、获取,设置和删除属性
// Get a attribute ( If the attribute is non-value attribute (eg. checked, selected...), it will returns true or false)
$value = $e->href;
// Set a attribute(If the attribute is non-value attribute (eg. checked, selected...), set it's value as true or false)
$e->href = 'my link';
// Remove a attribute, set it's value as null!
$e->href = null;
// Determine whether a attribute exist?
if(isset($e->href))
echo 'href exist!';
②、魔术属性

属性名 用法
$e->tag 读取或者写入元素的标签名.
$e->outertext 读取或者写入元素以外的html文本
$e->innertext 读取或写入元素内的文本
$e->plaintext 读取或者写入元素的纯文本
③、小贴士

3.5、如何遍历 DOM 树?
①、背景知识
// 如果你不熟悉DOM树, 可以点击这里知道更多
// Example
echo $html->find("#div1", 0)->children(1)->children(1)->children(2)->id;
// or
echo $html->getElementById("div1")->childNodes(1)->childNodes(1)->childNodes(2)->getAttribute('id');
②、遍历 DOM 树
你还可以调用驼峰命名转换.
模块 描述
mixed$e->children ( [int $index] ) 如果索引(index)被设置将返回N个子对象,如果没有将返回数组(array of children).
element$e->parent () 返回父级元素
element$e->first_child () 返回第一个子元素,如果没有找到将返回空(null)
element$e->last_child () 返回最后一个子元素,如果没有找到将返回空(null)
element$e->next_sibling () 返回下一个同级元素,如果没有找到将返回空(null)
element$e->prev_sibling () 返回上一个同级元素,如果没有找到将返回空(null)
3.6、如何抛出 DOM 对象的内容?
①、捷径
// Dumps the internal DOM tree back into string
$str = $html->save();
// Dumps the internal DOM tree back into a file
$html->save('result.htm');
②、面向对象
// Dumps the internal DOM tree back into string
$str = $html;
// Print it!
echo $html;
3.7、如何自定义解析行为?
回调函数
// Write a function with parameter "$element"
function my_callback($element) {
// Hide all tags
if ($element->tag=='b')
$element->outertext = '';
}
// Register the callback function with it's function name
$html->set_callback('my_callback');
// Callback function will be invoked while dumping
echo $html;