程序员 第12章 设计一个URL短链服务
程序员 第12章 设计一个URL短链服务
一、什么是 URL 短链
URL 短链,就是把原来较长的网址,转换成比较短的网址。
我们可以在短信和微博里可以经常看到短链的身影。
如下图,我随便找了某一天躺在我短信收件箱里的短信。

上图所示短信中
https://j.mp/38Zx5XC
就是一条短链。
用户点击蓝色的短链,就可以在浏览器中看到它对应的原网址:
https://activity.icoolread.com/act7/212/duanxin/index
那么为什么要做这样的转换呢?来看看短链带来的好处:
在微博,Twitter 这些限制字数的应用中,短链带来的好处不言而喻: 网址短、美观、便于发布、传播,可以写更多有意义的文字;在短信中,如果含长网址的短信内容超过 70 字,就会被拆成两条发送,而用短链则可能一条短信就搞定,如果短信量大也可以省下不少钱;我们平常看到的二维码,本质上也是一串 URL,如果是长链,对应的二维码会密密麻麻,扫码的时候机器很难识别,而短链则不存在这个问题;出于安全考虑,不想让有意图的人看到原始网址。
当然,以上好处也只是相对的,这不,随着微信扫码能力的提升,微信已经开始取消短链服务了。

二、短链跳转主要原理
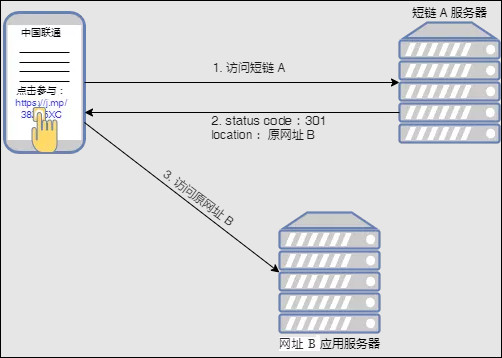
客户端(或浏览器)请求短链:https://j.mp/38Zx5XC
短链服务器收到请求后,返回 status code: 301 或 302,说明需要跳转,同时也通过 location 字段告知客户端:你要访问的其实是下面这个长网址:https://activity.icoolread.com/act7/212/duanxin/index
客户端收到短链服务器的应答后,再去访问长网址:https://activity.icoolread.com/act7/212/duanxin/index
实际浏览器中的网络请求如下图:
三、URL 短链设计的需求
3.1、功能性需求
给定原始的长 URL,短链服务能生成比它短且唯一的 URL
用户点击短 URL, 能跳转到长原始的长 URL
短 URL 经过一定时间后,会过期
接口需要设计成 REST API
3.2、非功能性需求
高可用:服务不能存在单点故障
高性能:生成短 URL 的过程,以及从短 URL 跳转到原始 URL 要近实时
安全:短链不可被预测,否则简单的遍历就能把所有短链都遍历完,空耗系统资源
四、系统容量预估
我们知道,做系统架构的时候,应该要让系统能扛住两方面的 “压力”:写请求的压力和读请求的压力。
写请求是指将长 URL 转换成短 URL,并将短 URL 存到数据库。
而读请求是指用户点击短 URL ,系统接到请求,从数据库中找到对应的长URL,返回给用户。
对于一个 URL,通常情况下我们把它一次性转换好后,把它存到数据库就完事了(“写”)。
接下来运营就会通过诸如短信、社交媒体等渠道将含有短链的内容发送给不同的用户,然后对内容感兴趣的用户会去点击该短链,继而跳转到目标页面(“读”)。
这个系统的读请求要远高于写请求,是一个 “Read-Heavy” 的系统。
这里,我们假设读写比是 100 : 1。
假设,我们的系统 1 个月需要处理 30 M(3000万)的写请求(长链生成短链服务),那么按照 100 : 1 的读写比例,我们每个月需要处理 URL 跳转的次数为:
100 * 30 M = 3B (30 亿)
进而,我们可以估算出每秒需要处理的请求数(QPS):
每秒的写请求(长链生成短链):
30 M/ (30 days* 24 hours* 60 min* 60 sec) ≅ 12 requests/second
每秒的读请求(短链跳转长链):
100 * 12 requests / second = 1200 requests/second
接下来再估算一下需多少的存储空间。
假设我们会默认保存 5 年内的短链转换记录,那么 5 年内产生的 URL 数量:
30 M * 12 * 5 = 1,800,000,000
那么短链应该设计成多长,才能表示这 5 年内的这 18 亿的 URL 呢?
通常短链是用 [0-9], [a-z], [A-Z] 这 62 个字符的组合来表示的,那么长度是 N 的短链可以映射的 URL 数量如下图:

所以,理论上我们的短链设计成 6 个字符就能满足需求了。
接下来,我们再假设数据中的一条记录的平均长度为 500 bytes(每条记录包含长 URL ,短 URL,记录创建时间,过期时间等信息)。那么,存储空间至少需要:
30 M * 12 * 5 * 500 = 0.9 T
再预估一下需要多大的网络带宽。
入网带宽:
12 * 500 bytes = 6 KB/s = 48 Kbps
出网带宽:
1200 * 500 bytes = 600 KB/s = 4.8 Mbps
这里延伸一下:通常情况下,服务器云厂商的入网带宽是不收费的,而出网带宽需要计费。
出网带宽可以实时调整,我们可以读请求的根据实际情况,即时调整出网带宽。
入网带宽会根据入网带宽,做动态的调整。
比如阿里云的 ECS,如果出网带宽的峰值小于 10Mbps,那么入网带宽就是 10Mbps,当出网带宽峰值大于 10Mbps时,入网带宽会调成和出网峰值相等的带宽。
另外,为了保证读请求的快速响应,我们还需要把一些经常访问的记录在内存中缓存起来。
根据 2-8 原则,我们把每天访问量前 20% 的记录缓存起来,那么需要的内存空间为:
100 * 30 M / 30 * 0.2 * 500 bytes = 10 G
综上,我们预估的与系统容量相关的各参数罗列如下:
每月长链生成短链的请求量:30 million
每月短链跳转长链的请求量:3 billion
读写请求比:100:1
每秒长链生成短链的请求量:12 requests/second
每秒短链跳转长链的请求量:1.2K requests/second
5 年内生成的 URL 短链数:1.8 billion
存储长短链映射关系的一条记录所需的空间:0.5K bytes
5 年内所需的存储空间: 0.9 T bytes
出网带宽:4.8 Mbps
缓存空间:10 G
五、API 设计
接口 1:根据原始 URL,生成短链
POST api/v0/shorten
Parameters
apiKey(String): 开发者密钥,用于接口监控和限流,参数不为空。
originalUrl(String): 原始 URL,参数不为空。
expireDate(Long):短链过期时间,默认保留 5 年,为可选参数。
Response
shortUrl(String): 生成的短链
接口 2:根据短链,返回原始 URL
GET api/v0/shortUrl
Parameters
shortUrl(String): 短链,不为空。
Response
originalUrl(String): 原始 URL
statusCode(String): 301(永久跳转) 或 302(临时跳转)
六、模块详细设计
设计短链生成算法
设计的短链生成算法,本质上是为了寻找一种映射关系,能将原始 URL 和生成的短链对应起来。
下面我们来分析一下目前短链生成算法一些主流的方案。
6.1、方案1:Hash 算法
最容易想到的是用 MD5 算法。
输入的长 URL 经过 MD5 算法的处理,会输出一串长度为 128 bit(16 B)的字符串。
128 bit 的 MD5 经过 Base62 转换,会生成 22 位的字符串。
What's the f**k? 怎么一顿骚操作之后反而变长了?
由于我们的短链长度是 6 位,一种方案是,我们可以从 22 位字符中取出前 6 位即可。
那么问题来了,这种操作引起 Hash 冲突的概率还是挺高的,就是说两个长 URL 经过 MD5 后,再经过 Base62 转换,生成串 A 和 B,如果 A 和 B 的前 6 位一样,即使后面的 16 位有差别,那么两个原本不一样的 URL 还是会映射到同一个短链上。这是不允许的。
为解决这个问题,我们可以在检测到冲突时,在输入的原始 URL 后面拼接一个特殊的标记,比如:[精确到毫秒的时间戳] 或 [客户端 IP],然后重新 Hash,这样冲突的概率就会降低,如果碰上好运再发生冲突,那就继续用一样的方式在 URL 后再加标记。对应的,通过短链获取长链时,我们需把长链尾部这些特殊标记去掉。
可以看出来,MD5 这种解决方案,不太优雅,而且效率不高。
一种改进的方案是采用 Google 的 MurmurHash。
MD5 是加密型哈希函数,主要关注加解密的安全性,所以会牺牲很多性能。而 MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。与其它流行的哈希函数相比,对于长度较长的 key,MurmurHash 的随机分布特征表现更良好,发生 Hash 碰撞的几率更低。比起 MD5,它的性能至少提升了一个数量级。
MurmurHash 的最新版本是 MurmurHash3,提供了 32 bit, 128 bit 这两种长度的哈希值。URL 经过 MurmurHash 计算后会生成一个整数。32bit 可以表示的数值范围为 0 ~ 4294967295, 约 43 亿,而基于我们前面的估计,系统 5 年内生成的 URL 数量约 18 亿,所以选择 32bit 的哈希值就足以满足需求了。
接下来,我们需要把经过 MurmurHash 生成的数字转化为 Base62 的字符。即 10 进制的 0~9 对应 62 进制的 0~9, 10 进制的 10~35 对应 62 进制的 a~z,10 进制的 36~61 对应 62 进制的 A~Z。假设长 URL 经过 MurmurHash 后生成的数字为:2134576890, 那么经过转换后生成的短链为 2kssXw,转换过程如下:
这样,基于 MurmurHash 的方案已经能较好地满足需求了。在系统运行前期,由于 43 亿的 Hash slot 没有完全填满,所以一般不会出现 Hash 冲突,系统运行 5,6 年后,由于 Hash slot 不断被占用,可能会出现一些 Hash 冲突。这时,一方面,我们需要删除过期的短链(超过 5 年),释放一些 Hash slot,另一方面,出现冲突的时候也可以按照上述原 URL 后面拼接特殊标记的方式,重新计算 Hash 值。
6.2、方案2:全局自增 ID
不同于 Hash 算法,全局自增 ID 的方案不需要对长 URL 进行 Hash 转换。
因为 ID 全局自增且唯一,它天然就能确保一个 ID 只映射一个长 URL,不存在之前 Hash 方案中存在的多个长 URL 可能映射到同一个短链的问题。
基于全局自增 ID 方案的整体设计思路是这样的:我们先维护一个 ID 自增生成器,这个自增生成器采用一定的算法来生成全局自增的 ID,比如用数据库的自增 ID,或用 Zookeeper 来计数,或用 Redis 中具有原子操作的 incby,或使用 Java 中的 AtomicLong,或采用基于 CAS 的乐观锁思想自己实现一个自增计数算法,等等。总之,经过 ID 生成器后,它可以输出 1、2、3、4…这样自增的整数 ID。
当短链服务接收到一个原始 URL 转短 URL 的请求后,它先从 ID 生成器中取一个号,然后将其转化成 62 进制表示法,我们把它称为短链的 Key (比如: 2kssXw),再把这个 Key 拼接到短链服务的域名(比如新浪微博短域名 http://t.cn/)后面,就形成了最终的短网址,比如:http://t.cn/2kssXw。最后,把生成的短 URL 和对应的原始 URL 存到数据库中。
基于全局自增 ID 的方案,整体的设计思路很清晰,实现起来难度也不大,比如采用 Redis 作为发号器,单机的 QPS 可以逼近 10w,所以性能也是很不错的。
但是,这种方案还存在两方面的问题。
问题 1:发号器的 ID 是在自增的,来一个 URL 请求,不管 URL 有没有重复,发号器每次都会发一个不一样的 ID。这样,如果相同的 URL 多次请求短链服务,每次都会生成不一样的短链。如果有人搞破坏,用同一个 URL 反复请求短链服务,就可以很轻松地把短链服务的 ID 资源耗尽。
问题 2:短链后面的 ID 单调增长,太有规律了,可以被预测到。这样攻击者就可以很容易猜到别人的短链,进而可以发起对原网址的非正常访问。
那么,怎么解决这两个问题呢?
对于问题 1,我们第一时间的反应,就是给数据库中的长 URL 字段也加一个索引,确保重复的长 URL 无法插入到数据库,保证了短 URL 和长 URL 之间一对一的映射关系。但是,由于多加了一个长 URL 字段的索引,一方面创建索引树需占用更多的存储空间,另一方面,由于索引字段内容太多,导致数据库的一个 Page (比如 MySQL 的 Innodb,一个 Page 默认是 16K)能包含的记录数减少,当有新的插入、删除操作时,就很容易产生分页,导致性能的下降。
其实,我们也可以不去处理重复 URL 的问题。实际上,多数情况下用户只关心短链能否正确地跳转到原始网址。至于短链长什么样,重不重复,用户其实根本就不 care。所以,即便是同一个原始 URL,两次生成的短链不一样,也并不会影响到用户的使用。在这个思路下,我们就可以不用去给长 URL 字段加索引了。
但是,长 URL 字段不加索引后,我们就要做些额外的工作,来防止同一个长 URL 转短链的次数太多,导致短链 ID 资源耗尽的问题。我们可以在短链服务前加一个布隆过滤器(Bloom Filter)。布隆过滤器基于位操作,即省空间,操作效率也高。当长 URL 转换短链的请求打过来的时候,先判断布隆过滤器里有没有这个 URL, 如果没有,那么说明这个长 URL 还没有转换过,接下来短链服务就给它生成一个对应的短链。如果布隆过滤器判断该 URL 已经存在了,那么就不再给它分配新的自增 ID。
不过,布隆过滤器有一个“假真”的特性:如果它判断过滤器中存在某个 URL,而事实上这个 URL 却可能不存在。为什么会这样?因为多个 URL 经过散列后,某些比特位会被置为 1,而这些是 1 的比特位组成的散列值可能刚好和这个待判断 URL 的散列值一样。不过呢,这个概率可以通过调整过滤器的比特位长度,变得很小很小,小到可以忽略不计。
至于问题 2,我们可以引入随机算法来解决。在得到自增 ID 对应的 62 进制的字符串后,再将字符串中的每个字符转换为二进制数。然后在固定位,比如第 5 位,第 10 位,第 15 位,... 等等,插入一个随机值即可。相应的,解码的时候,需要将固定位的值去掉。
6.3、方案3:离线生成 Key
方案 1 和 2 都是基于 Online 的方案,即来一个请求,根据一定的算法实时生成一个短链。为了进一步提升短链 Key 的生成效率,而不必非得用到的时候才去生成 Key,我们可以换一个思路:通过 Offline 的方式,预先生成一批没有冲突的短链 Key,等长 URL 转短 URL 的请求打过来的时候,就从预先生成的短链 Key 中,选取一个还没使用的 Key,把映射关系写到数据库。这样,我们就完全不用担心方案 1 中出现的 Hash 冲突问题。
我们把这种通过 Offline 方式生成短链 Key 的服务,叫做 Key Generating Service,简称 KGS。通过 KGS 生成的短链 Key,放在 Key DB 中。
我们知道,基于 Base62,总共可以产生 62 ^ 6 种不同的 Key, 所以 KeyDB 中存储所有 6 位 Key 所需的空间为:
(62 ^ 6) * 6 byte ≅ 317 G
另外,对比基于自增 ID 的方案,增加了 2 次同步的网络请求
(WebServer -> KGS 和 KGS -> KeyDB)。那么,这 2 次请求是否有办法优化?
我们可以采用“预加载”的方法,让 KGS 每次从 KeyDB 请求 Key 时,不要只拿一个,而是一次多拿一些,比如 1000 个,然后放进 KGS 服务器的本地内存中,数据结构可以是阻塞队列。KeyDB 会将这 1000 个 Key 标记为已使用。
更进一步,其实 WebServer 也可以从 KGS 中一次多拿一些未使用的 Key,比如每次返回 20 个,放在 WebServer 的本地内存。当 WebServer 阻塞队列中的 Key 快用完的时候,再向 KGS 请求再拿 20 个 Key。同样的,KGS 中的 Key 快用完的时候,再向 KeyDB 请求再 1000 个 Key。这样,经过“预加载”优化之后,2 次同步网络请求就变成 0 次,达到了将同步请求“异步化”的效果。
那么,“预加载”会有什么问题呢?毕竟数据是放在内存中的,如果服务器因故障重启,那么这些“预加载”的 Key 就丢失了,虽然这些 Key 还没有真正被使用,但是 KeyDB 已经将它们标记为已使用,所以这些丢失的 Key 最后就被浪费掉了。
那怎么应对这种意外情况呢?
一种办法是,KGS 从 KeyDB 批量拿 Key 的时候,KeyDB 不要先将这些Key 标记为已使用。KGS 和 WebServer 在真正使用了一个 Key 之后,再异步地将 KeyDB 中的这个 Key 标记为已使用。
另一种办法是:不处理。相对于 568 亿的总量,偶尔浪费 1000 个 Key,其实影响不大,况且服务器又不是天天宕机重启。
所以说,架构其实是一种根据实际情况,不断权衡利弊的过程。
七、数据库表设计
有两个公用的数据库:AppKeyDB 和 UrlMappingDB 。AppKeyDB 用于管理用户的 AppKey,防止非法用户调用长链转短链接口。UrlMappingDB 用于存放短链 Key 和原始 URL 的映射关系。
如果我们采用基于 KGS 的方案,还需要设计一个数据库:KeyDB,用于存放预先生成的短链 Key。
AppKeyDB 中只有一张表:t_user_appkey
CREATE TABLE `t_user_appkey` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`app_key` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`status` bit(1) NULL DEFAULT b'0' COMMENT '账号状态:0 正常,1 异常',
`gmt_create` datetime NULL DEFAULT NULL COMMENT '创建日期',
PRIMARY KEY (`id`) USING BTREE
)
UrlMappingDB 中只有一张表:t_url_mapping
CREATE TABLE `t_url_mapping` (
`key` varchar(6) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '短链key',
`original_url` varchar(512) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '原始url',
`gmt_created` datetime NULL DEFAULT NULL COMMENT '创建时间',
`gmt_expired` datetime NULL DEFAULT NULL COMMENT 'key失效日期',
PRIMARY KEY (`key`) USING BTREE
)
KeyDB中有两张结构一样的表:t_valid_keys 和 t_unvalid_keys。
表结构很简单,只有一个字段 key。
t_valid_keys 用于存放还没有被分配掉的短链 Key,可以预先生成。
单机情况下,一般不会一下子生成所有的 key,而是根据规则分批去生成 Key,比如固定某两位生成一批,这样 t_valid_keys 单表的记录数量最多在千万的量级。
CREATE TABLE `t_valid_keys` (
`key` varchar(6) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '有效的key',
PRIMARY KEY (`key`) USING BTREE
)
t_unvalid_keys 用于存放已经使用的 Key。KGS 每次向 t_valid_keys 请求没被使用的 key,请求返回的同时将这些 Key 写到 t_unvalid_keys 中。当 t_unvalid_keys 中的数据达到千万的量级后,需要分表,或者一开始就设计好分表规则。
CREATE TABLE `t_unvalid_keys` (
`key` varchar(6) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '失效的key',
PRIMARY KEY (`key`) USING BTREE
)
八、考虑系统扩展的问题
至此,我们分析了短链服务主要模块的设计。接下来再来考虑系统的可用性和性能问题。
8.1、数据库的高可用
基于前面的系统容量预估,我们知道 5 年内所需的存储空间是 TB 级别的,其中最主要是要存储长 URL 和短 URL 之间的映射关系,单个 UrlMappingDB 和单张 t_url_mapping 是搞不定的,这时就需要考虑分库分表的方案。而且,在短链服务这个项目背景下,一开始就需要设计分库分表的方案。分库主要是为了解决数据库“写”的压力,分表是为了解决“读”的压力。
那么,需要分几个库,几个表?分库分表的策略是什么?
分库的策略一般是垂直分库,不同的服务对应不同的数据库。
短链服务主要需要两个数据库:保存长短链关系的 UrlMappingDB 和 保存短链 Key 使用记录的 KeyDB。
考虑到单个 UrlMappingDB 的数据量比较大,同时分散写数据库的压力, 我们还需继续将 UrlMappingDB 拆成多个库。
分库的个数需结合分表的个数来考虑。
至于分表,一个原则就是尽量让单表的记录在 1 千万以下(至于深层的原理,可以结合 Page 大小和 B+ 树索引机制)。
短链服务中,可以分成 256 张表,这样每张表的记录数为:
1.8 billion / 256 = 7, 031, 250
即单表记录约为 700 万。
t_url_mapping 分表的 key 可以使用短链 Key 或创建时间来计算 hash,通过一致性 Hash 算法把记录路由到对应的分表。
这样,一个分库分表的规则就是:把 UrlMappingDB 分成 4 个库,即:
UrlMappingDB_00, UrlMappingDB_01, UrlMappingDB_02,UrlMappingDB_03。各个分库和分表的对应关系如下:
分库 分表
UrlMappingDB_00 t_url_mapping_000 ~ t_url_mapping_063
UrlMappingDB_01 t_url_mapping_064 ~ t_url_mapping_127
UrlMappingDB_02 t_url_mapping_128 ~ t_url_mapping_191
UrlMappingDB_03 t_url_mapping_192 ~ t_url_mapping_256
OK, UrlMappingDB 的分库分表已经搞定。但是目前数据还存在单点故障的风险,因为我们没有做备份,如果某个分库所在的机器宕机了,那么这个分库的所有数据就丢了。所以我们还需要将分库的数据 copy 一份或多份,做好冗余。
数据的备份可以采用常见的中心化的主从架构,也可以采用基于去中心化的 NWR 机制。至于主从之间怎么同步数据,用什么共识机制来选主,NWR 机制下多个节点之间怎么同步数据等问题,这里就不再展开了,后面有单独的文章来探讨这些话题。
8.2、发号器的高可用
我们在设计短链生成算法的环节,介绍了 3 种短链生成算法,方案 1 使用 MurmurHash,做成分布式服务相对简单,一样的服务只要多部署几台机器,前面加个 Nginx 做负载均衡就可以了。
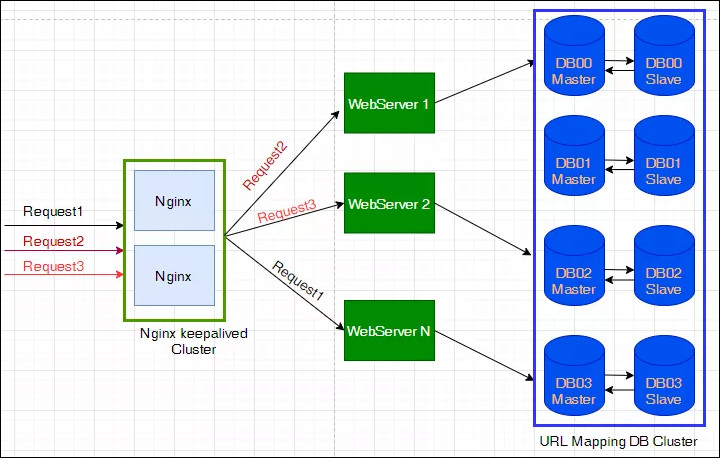
如果用自增 ID 方案来做发号器,怎么做分布式高可用方案呢?
我们可以做 10 个发号器,分别为 Sender_00 ~ Sender_09, Sender_00 负责发出尾号是 0 的 ID,Sender_01 负责发出尾号是 1 的 ID,以此类推,Sender_09 负责发出尾号是 9 的 ID。每个发号器的步长是 10,就是说,如果某次 Sender_00 发送了 200,那么下一次它会发送 210。这样每个发号器产生的 ID 互不冲突。具体的实现,可以基于本机内存(AtomicLong) + 记 Log 实现,也可以基于 Redis 的累加器实现,或基于 ZK 计数。下图使用 Redis Cluster 实现。我们在 Redis 中设置 10 个不一样的 key,每个 key 相当于一个发号器,步进长度为 10。
如果使用 KGS 方案作为发号器,考虑到 KGS 可以批量发号,批量拿号后完全是内存操作,少了网络 IO 的开销,所以 KGS 服务器做主备架构就可以了,如果压力上来的时候,可以做类似多个发号器的架构。架构图如下:

8.3、缓存机制
短链服务是一个典型的读多写少的应用,对于这种 Read Heavy 型的应用,显然加缓存可以大大提升读请求的性能。以下是加入缓存的架构图。

再说说缓存失效相关的问题。
我们一开始说的需求里说短链是有过期时间的,用户可以自己设置过期时间,不设置的话系统会默认保留 5 年。短链过期后,我们需要从 UrlMappingDB 中将该短链和原始 URL 的绑定关系解除,这样短链就可再次投入使用了。
问题是:短链过期的时候,是先删缓存呢,还是先删数据库记录?
如果是先删缓存再删数据库,会发生什么问题?
如下图所示,假设短链 2kssXw 过期需要删除,在 T1 时刻删除缓存成功, T3 时刻删除数据库记录成功。

在高并发环境下,T2 时刻来了一个短链跳转的请求,需要从缓存里根据短链 2kssXw 去找对应的原始 URL,但是这时缓存中已经没有这个键值对了,所以又会去数据库中查找,看是否存在含有 2kssXw 的记录,不幸的是,这时数据库中 2kssXw 对应的记录还没有删掉,所以又被加载到了缓存中。到了 T3 时刻,数据库中 2kssXw 对应的记录才真正被删掉,但这时缓存中却存在 2kssXw 对应的数据。这就造成了缓存和数据库的数据不一致。
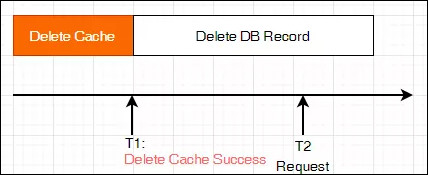
所以,常用的方案是先删数据库记录,再删缓存。如果需要再保险一点,再启用延时双删,或者直接同步数据库的 binlog 来删缓存。
8.4、服务限流
为了防止一些异常的流量占用系统资源,让正常的请求能够得到服务器的 “雨露均沾”,让系统运行地更健壮,所以一个系统除了正常的功能,还需要加入一些限流策略。
可以基于 Nginx 来做限流,可以对某些 IP 实现限流,比如 1s 内同一个 IP 只能请求 5 次;也可以限制一段时间内的连接总数,比如 1s 内,只接受 1000 个IP 的连接;也可以实现基于黑白名单的限流。
如果需要更细粒度的对具体服务和接口的限流策略,可以参靠 Guava 的 RateLimiter,再定制自己的策略,在网关层实现限流。感兴趣的同学可以去了解更多的细节。