正则表达式 第2章 元字符
正则表达式 第2章 元字符
一、普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
二、界定符
表示一个正则表达式开始和结束,通常使用 //
也可使用 ##、{}(由于{}可以表示正则符,所以不推荐用作界定符)
三、 非打印字符
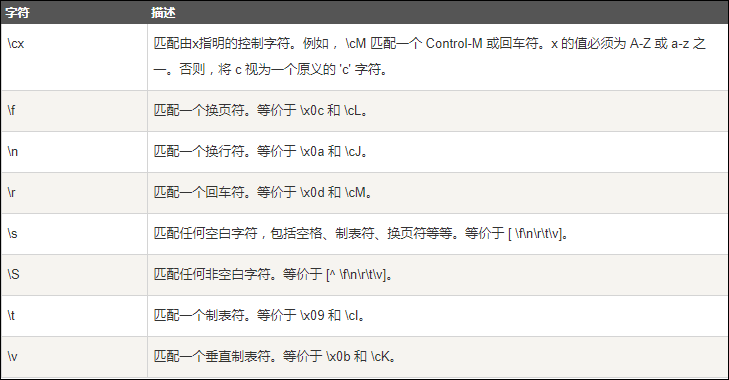
四、特殊字符
所谓特殊字符,就是一些有特殊含义的字符。
若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。
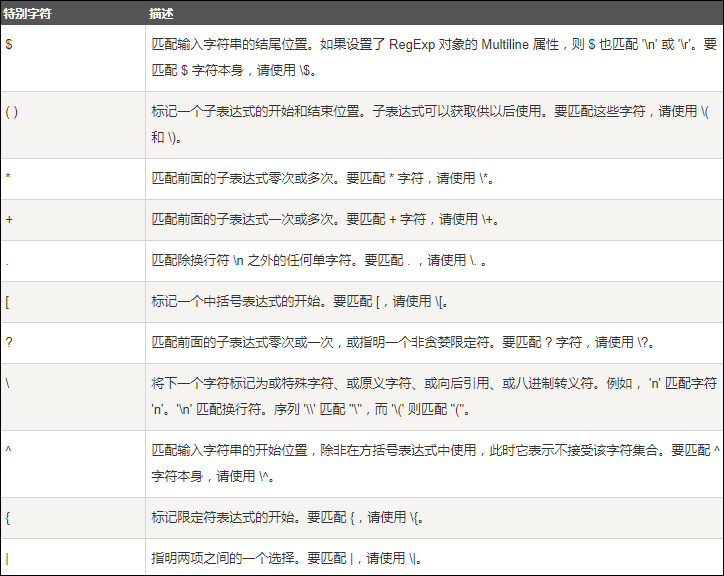
五、限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。

六、定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。

注意:不能将限定符与定位符一起使用。由于在紧靠换行或者字边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式。
var str = "bloglulu";
var patt1 = /lulu\b/; //匹配以lulu结尾的字符串
document.write(str.match(patt1)); //lulu
var str = "lulublog";
var patt1 = /\blulu/; //匹配以lulu开头的字符串
document.write(str.match(patt1));
七、修正模式
U 懒惰匹配、i 忽略英文字母大小写、x 忽略空白、s 让元字符 '.'匹配包括换行符在内的所有字符
① 贪婪匹配(默认)与懒惰匹配 U
贪婪匹配:匹配结果存在歧义时取其长
懒惰匹配:匹配结果存在歧义时取其短
实例:
$pattern = '/lulublog.+123/';
$subject = 'I love lulublog_123123123123';
$matches = [];
preg_match($pattern, $subject, $matches);
返回:

实例:
$pattern = '/lulublog.+123/U';
$subject = 'I love lulublog_123123123123';
$matches = [];
preg_match($pattern, $subject, $matches);
返回:

② 忽略大小写
实例:
$pattern = '/luLuBlog.+123/i';
$subject = 'I love lulublog_123123123123';
$matches = [];
preg_match($pattern, $subject, $matches);
返回:

③ 忽略空白
实例:
$pattern = '/lu LuBl og.+123/ix';
$subject = 'I love lulublog_123123123123';
$matches = [];
preg_match($pattern, $subject, $matches);
返回:

八、反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。
缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
反向引用的最简单的、最有用的应用之一,是提供查找文本中两个相同的相邻单词的匹配项的能力。以下面的句子为例:
//查找重复的单词:
var str = "Is is the cost of of gasoline going up up";
var patt1 = /\b([a-z]+) \1\b/ig;
document.write(str.match(patt1));
([a-z]+) \1:捕获的表达式,正如 [a-z]+ 指定的,包括一个或多个字母。正则表达式的第二部分是对以前捕获的子匹配项的引用,即,单词的第二个匹配项正好由括号表达式匹配。\1 指定第一个子匹配项。
\b:字边界元字符确保只检测整个单词。否则,诸如 "is issued" 或 "this is" 之类的词组将不能正确地被此表达式识别。
g:正则表达式后面的全局标记 g 指定将该表达式应用到输入字符串中能够查找到的尽可能多的匹配。
i:表达式的结尾处的不区分大小写 i 标记指定不区分大小写。
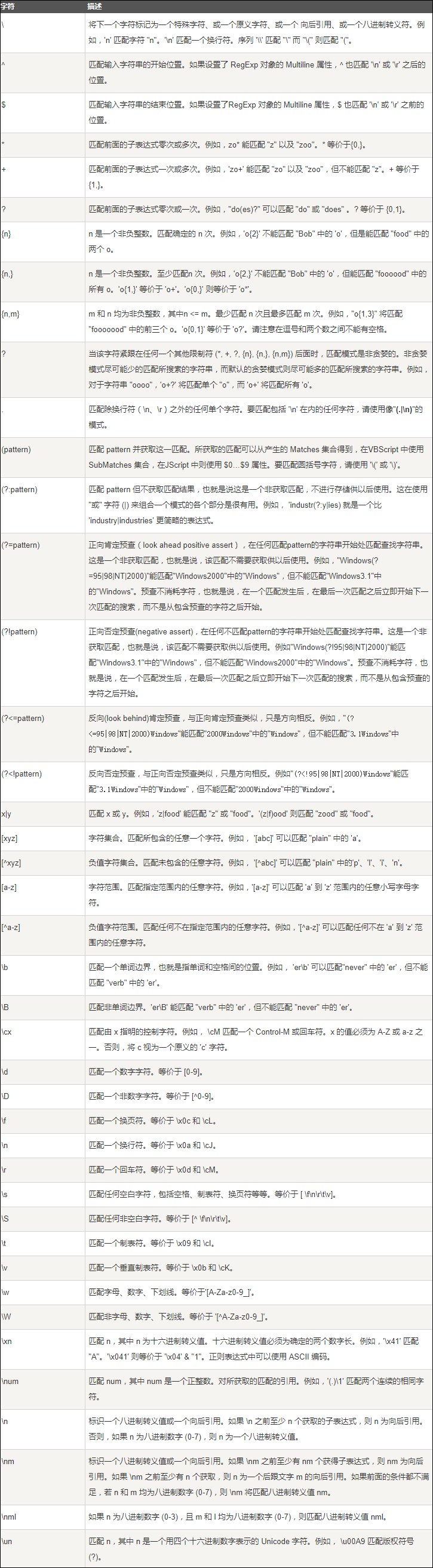
九、元字符
下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为: