elasticesearch 第7章 索引原理
elasticesearch 第7章 索引原理
下图描述了 3 个节点的集群,共拥有 12 个分片,其中有 4 个主分片(S0、S1、S2、S3)和 8 个副本分片(R0、R1、R2、R3),每个主分片对应两个副本分片,节点 1 是主节点(Master 节点)负责整个集群的状态。
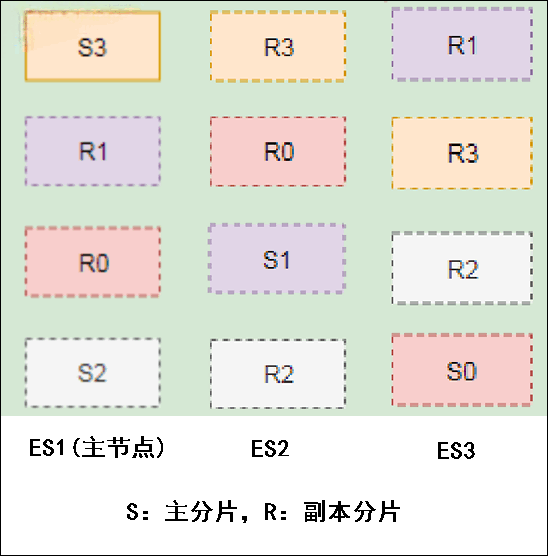
写索引是只能写在主分片上,然后同步到副本分片。这里有四个主分片,一条数据 ES 是根据什么规则写到特定分片上的呢?
这条索引数据为什么被写到 S0 上而不写到 S1 或 S2 上?那条数据为什么又被写到 S3 上而不写到 S0 上了?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。
实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
Routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。
Routing 通过 Hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数。
这个在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
由于在 ES 集群中每个节点通过上面的计算公式都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
在一个写请求被发送到某个节点后,该节点即为前面说过的协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。
假如此时数据通过路由计算公式取余后得到的值是 shard = hash(routing) % 4 = 0,则具体流程如下:
客户端向 ES1 节点(协调节点)发送写请求,通过路由计算公式得到值为 0,则当前数据应被写到主分片 S0 上。
ES1 节点将请求转发到 S0 主分片所在的节点 ES3,ES3 接受请求并写入到磁盘。
并发将数据复制到两个副本分片 R0上,其中通过乐观并发控制数据的冲突。一旦所有的副本分片都报告成功,则节点 ES3 将向协调节点报告成功,协调节点向客户端报告成功。